

DMTN-304
Processing DP0.2 at FrDF: A comparison with DP0.2 catalogs produced at IDF#
Abstract
The purpose of this note is to compare the final catalogs produced by the processing done in FrDF of the DP0.2 data with the reference catalogs produced at IDF.
Introduction#
In this note, we report the results of the comparison between DP0.2 catalogs produced at FrDF and the reference catalog produced at IDF.
In the context of the Data Preview 0.2 (DP0.2), the Data Release Production pipelines have been executed on the DC-2 simulated dataset (generated by LSST Dark Energy Science Collaboration (LSST DESC) et al. [2021]). This dataset includes 20,000 simulated exposures, representing 300 square degrees of Rubin Observatory images with a typical depth equivalent to five years of observations. DP0.2 was run at the Interim Data Facility, and the full exercise was independently replicated at FrDF (CC-IN2P3), as described in Le Boulc'h et al. [2024].
In this note, we will begin by describing the catalogs and explaining how we selected the data.
Then, we report the analysis performed on each table, focusing on two main objectives: assessing how the sources’ positions in the sky match, and comparing the sources’ fluxes (when applicable).
The data and notebooks used are available on CC-IN2P3 GitLab.
The catalogs in Qserv#
The catalogs have been ingested in Qserv [Wang et al., 2011] production instance at FrDF:
dp02_dc2_catalogs_frdf catalog produced at CC-IN2P3 (hereafter FrDF catalog)
dp02_dc2_catalogs catalog produced at IDF (hereafter IDF catalog)
For the FrDF catalog, two tables are missing (TruthSummary and MatchesTruth) because that tables require post processing before to be ingested in Qserv.
In the following image, you can see the number of lines per table in the FrDF and IDF catalogs. CcdVisit and Visit, produced by pipeline Step 7, have been produced twice at FrDF. For our purposes, the FrDF data have been filtered to remove the duplicate rows. This problem needs to be addressed: we have to be able to flag the invalid tables to detect them before the ingestion process.
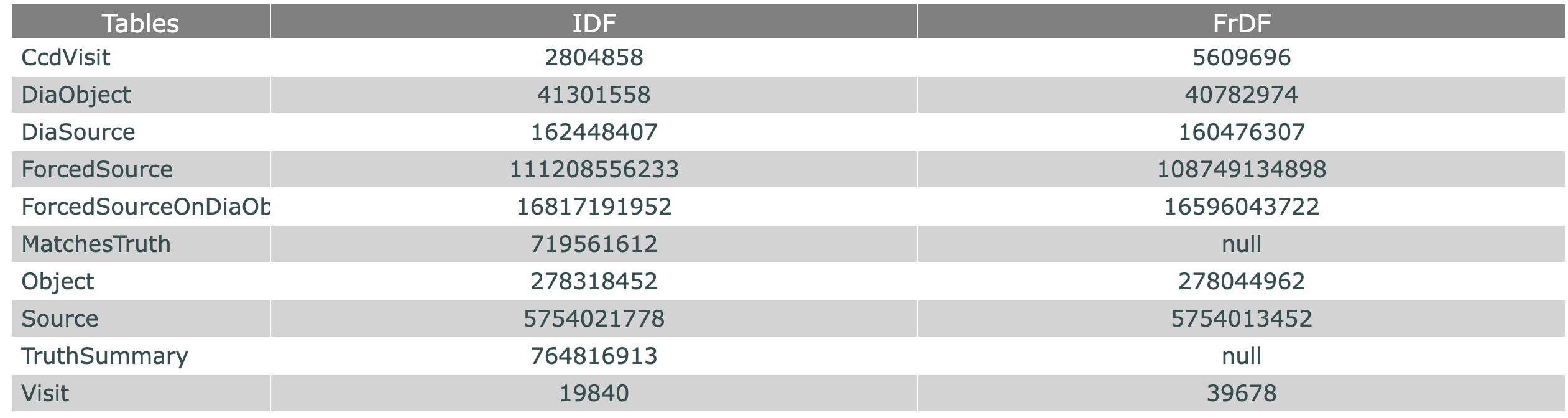
Fig. 1 Number of lines per table in DPO.2 FrDF and IDF catalogs.#
It is not possible to compare the full catalogs, so for the analysis reported here, we used subsamples of both catalogs, selected using a spatial query such as this:
SELECT <column1>, <column2>, ...,<columnN> from <table> where scisql_s2PtInCircle(<ra>, <decl>, 60.0, -30.0, 0.5) = 1 limit 5000000
We limited the number of retrieved lines to 5 million, but for tables with a large number of lines (sources), we also reduced the query radius: a radius of 0.5 degrees is too large, and the number of sources in the area defined by the circle largely exceeds the limits we imposed on the number of lines.
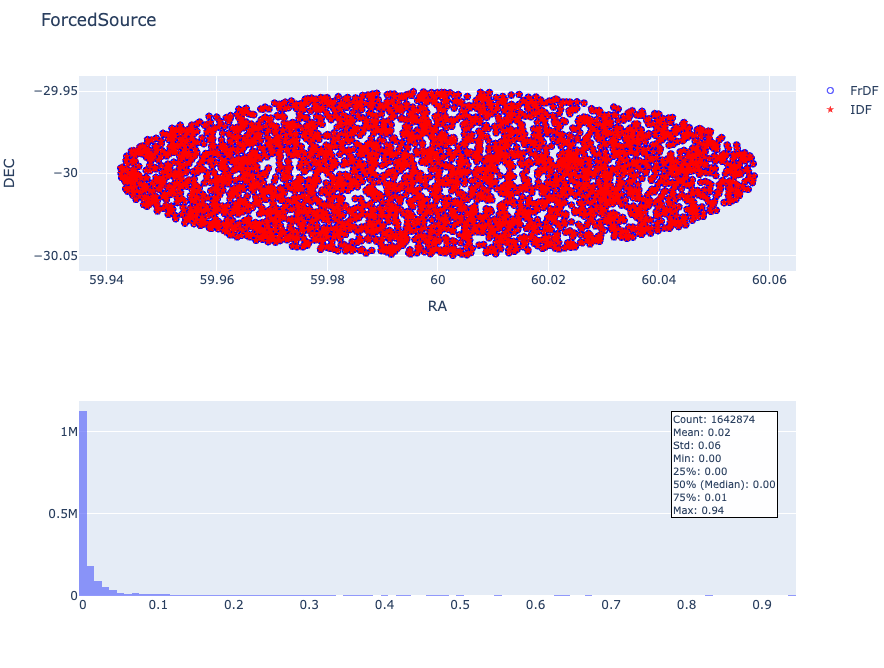
For this reason, the catalogs retrieved are not comparable because the sources in the tables do not cover the same region, as shown in the following image for the ForcedSource table retrieved with a radius of 0.5 degrees. In the image, the objects extracted from FrDF are shown in black, and the objects extracted from the IDF are shown in red.

Fig. 2 Example of source extraction not covering the same region.#
To reduce the data size, we also retrieved a subsample of columns (ra, dec, and fluxes). We retrieved all columns only for a few small tables.
The fluxes has been converted to AB magnitude using UDF SQL function scisql_nanojanskyToAbMag [1] integrated in Qserv.
All the queries used for each table are reported in query notebook.
The analysis has been performed offline: all the tables have been retrieved once and stored locally as FITS files (available in the ‘fits’ directory in the Gitlab repository).
For each table, a file called <df>_<table>.fits has been generated, and a new column (DF) has been added to each table, allowing easy identification of the data origin during analysis.
Topcat [2] has been used to quickly validate the retrieved datasets and to filter out duplicate lines in the Visit and CcdVisit tables.
Comparison#
For the analysis, there is an interactive notebook that allows table selection and the type of plot to generate. For each table, we also created a notebook (available in the notebook directory), and we generated an interactive HTML file with all the plots (coordinates and magnitudes), which is available in the HTML directory.
We performed a match between the catalogs to make correct correspondences between the rows and to avoid odd results (i.e., comparison between sources in different regions of the sky).
For this, we used the Astropy [3] module when the number of rows in the retrieved tables was the same (in this case, we reordered the tables to ensure matching rows). When the number of rows in the tables was not the same, we used Topcat STILTS [4] functions (as implemented in pystilts). We used STILTS because it allows the “symmetric match,” i.e., it allows only one match per source; with Astropy, this is not possible, and you can get multiple matches that could lead to wrong results.
However, even with these conditions, matching in the case of the ForcedSource table can be very difficult, if not impossible.
To better understand this point, see the following table and figures showing the data retrieved from three Qserv tables.

Fig. 3 Number of sources extracted from Object,Source and ForcedSource tables.#

Fig. 4 Comparison of the radii used for source extraction in the Object (green), Source (light pink), and ForcedSource (dark magenta) tables.#
Object table in 0.5deg radius (number of sources=395952)
Source table in 0.1deg radius (number of sources=561385)
ForcedSource table in 0.05deg radius (number of sources=1643290)
In ForcedSource we have 4 times more entries than Object table in a region 100 times smaller.
Taking a look to the density of source, we see how it could be complicated for a matching algorithm to find the good match. The following figures show the number of sources per “pixel” for the different tables. The pixel size used is 7.2 x 7.2 arcseconds.
Fig. 5 Source density in the Object table (in a 7.2 × 7.2 arcsecond ‘pixel’).#
Fig. 6 Source density in the Source table (in a 7.2 × 7.2 arcsecond ‘pixel’).#
Fig. 7 Source density in the ForcedSource table (in a 7.2 × 7.2 arcsecond ‘pixel’).#
You can see the number of sources per pixel on the scale to the right. ForcedSource has an incredibly high number of sources per pixel, in some cases, more than three thousand. It’s clear that a matching algorithm using a separation of 1 arcsecond as a parameter to match two points cannot be 100% reliable under these circumstances.
If we exclude the ForcedSource table, the matching algorithm worked as expected for the other tables.
Sources positions analysis#
To analyze how well the positions of the objects in the sky match, we compared RA and Dec, and we also analyzed the sky separation (i.e., the great-circle distance) estimated using Astropy.
c1 = SkyCoord(df[ra_1]*u.deg, df[decl_1]*u.deg, frame='icrs')
c2 = SkyCoord(df[ra_2]*u.deg, df[decl_2]*u.deg, frame='icrs')
sep=c1.separation(c2).degree
An exemple of the distribution of the sky separation is visible in the next figure.
Fluxes (magnitudes) analysis#
For the flux comparison, we converted nJy to AB magnitudes. For each table, we selected the flux columns and converted them to AB magnitudes using the UDF scisql_nanojanskyToAbMag available in Qserv.
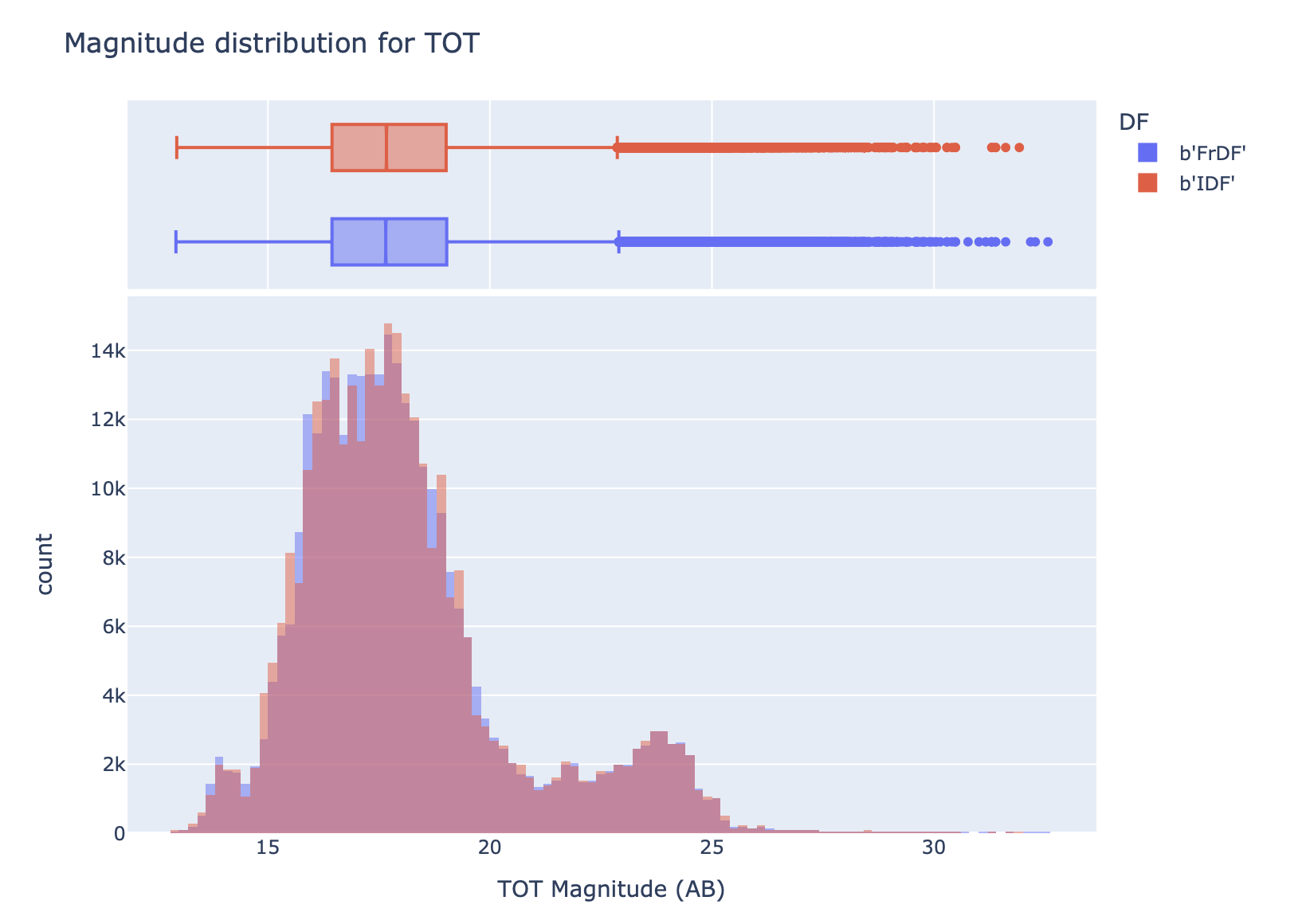
Then, for each magnitude, we plot the histogram and the box plot of the distribution for each catalog, as shown in the next figure.
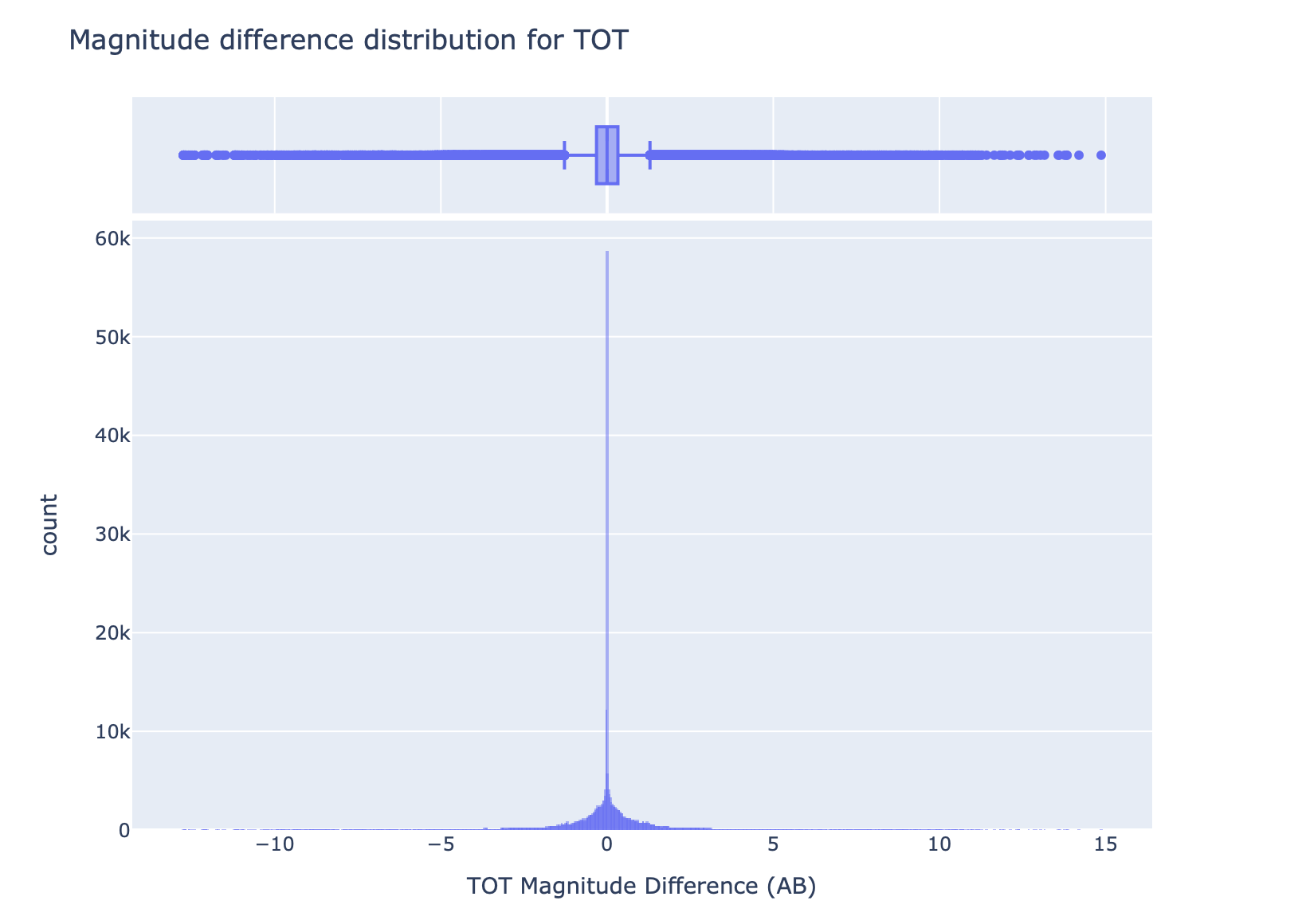
We also plot the histogram and box plot of the distribution of the magnitude differences, i.e., the differences calculated per matching source.
For reference, the following image explains the meaning of a box plot.
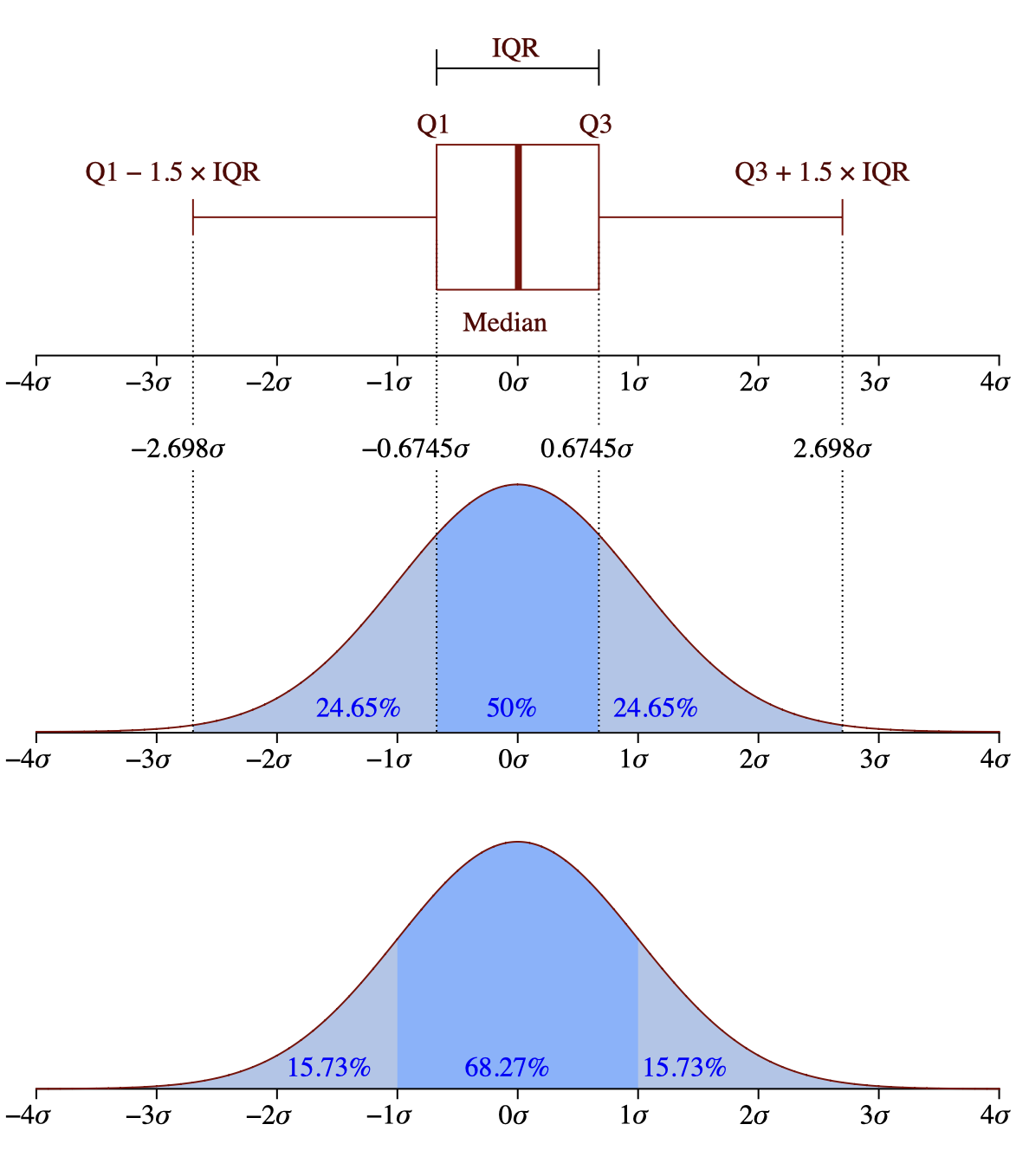
Results#
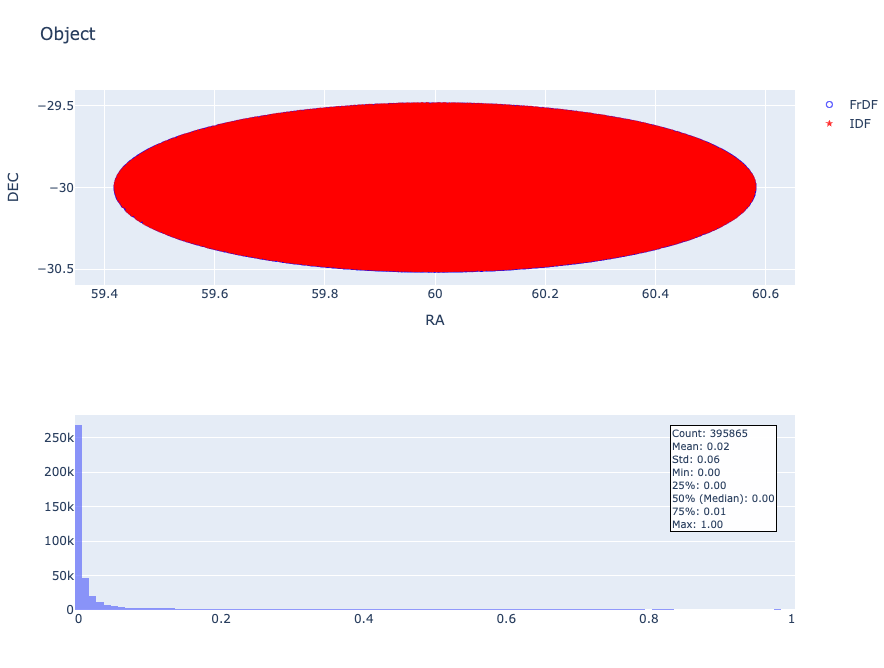
The results show very good compatibility between the catalog produced at FrDF and the one produced at IDF. The positions in the sky are almost identical, with very few differences generally limited to a small number of objects. For example, in the Object table, 80% of the 395,000 sources have a separation of less than 0.015 arcseconds, and 90% under 0.06 arcseconds. For some tables, there is no difference at all.
The results for magnitudes are also compatible, with very small differences. For each table, we report the main results in the next sections.
You can also check all the results for each table in the appropriate notebook linked in each table’s section.
Overall, the coordinates and magnitudes show a very good fit between the catalogs. However, we found some problems, listed here:
ForcedSourceOnDiaObject produced at FrDF has no fluxes; all the flux columns are set to NaN, which is probably linked to the JIRA ticket DM-35338.
As mentioned, Visit and CcdVisit have been produced twice; we need to define a correct procedure in the case of reprocessing to avoid this specific issue.
The Object table at FrDF shows holes around very bright sources. It is not clear why; it could be linked to changes in how the pipelines process data. To be investigated.
ForcedSource magnitudes show a larger distribution of differences, but, as mentioned above, this could be linked to a selection effect during the catalog matching.
Object Table#
The Object table contains astrometric and photometric measurements for objects detected in coadded images (990 columns).
We use a query to retrieve all the objects in the region defined by a circle of 0.5 degrees radius around the center point with coordinates (60.0, -30.0) degrees.
But the number of lines retrieved from both catalogs is not the same: 395,952 for FrDF and 396,373 for IDF. This means that the pipelines produced two different catalogs. Looking at the source distribution, we can see that in the FrDF table there are a few holes around bright sources.
The following figures show the sky maps for the sources produced at FrDF (in blue) and those produced at IDF (in red).
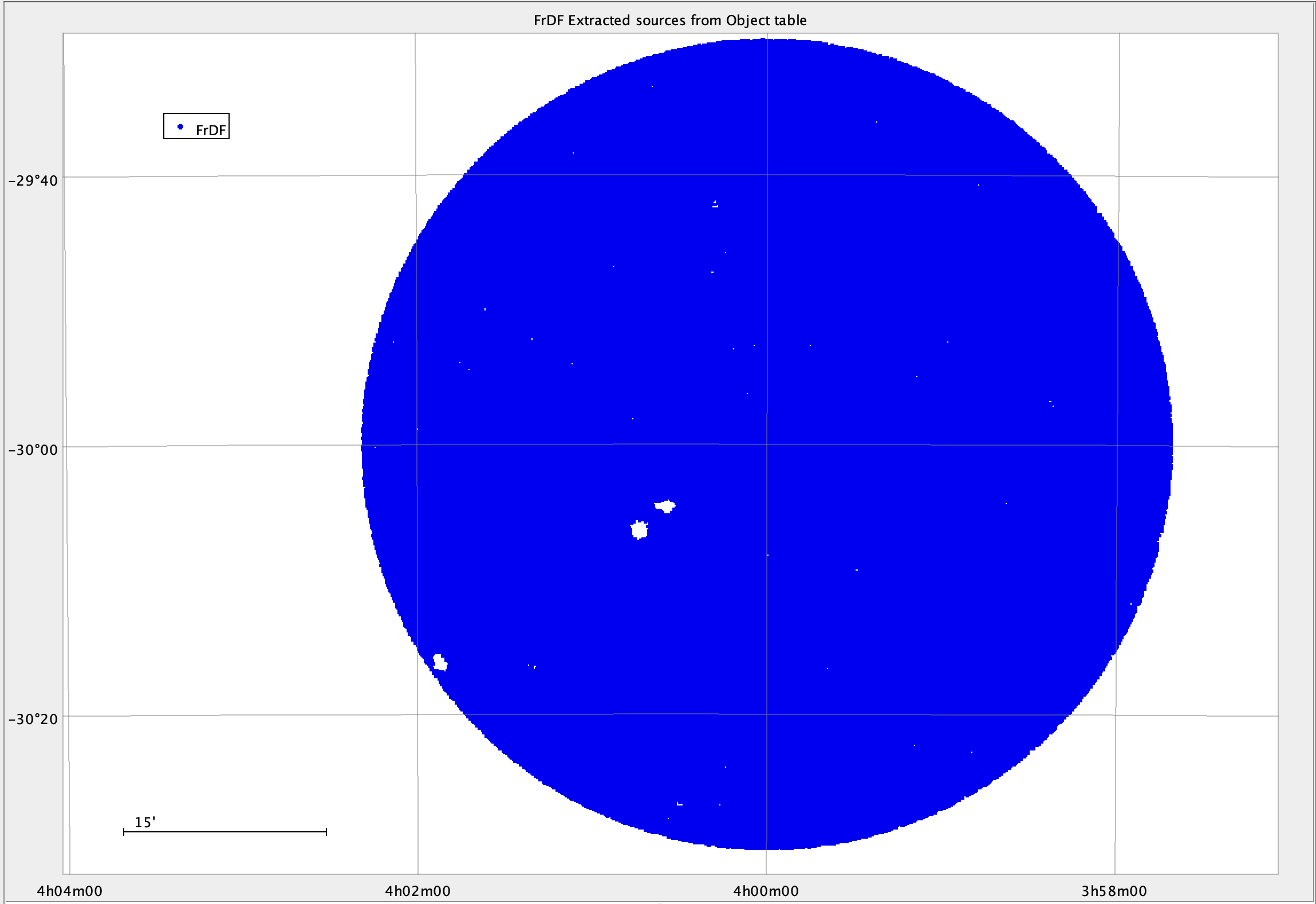
Fig. 8 Object’s sources from FrDF DP0.2 catalog#
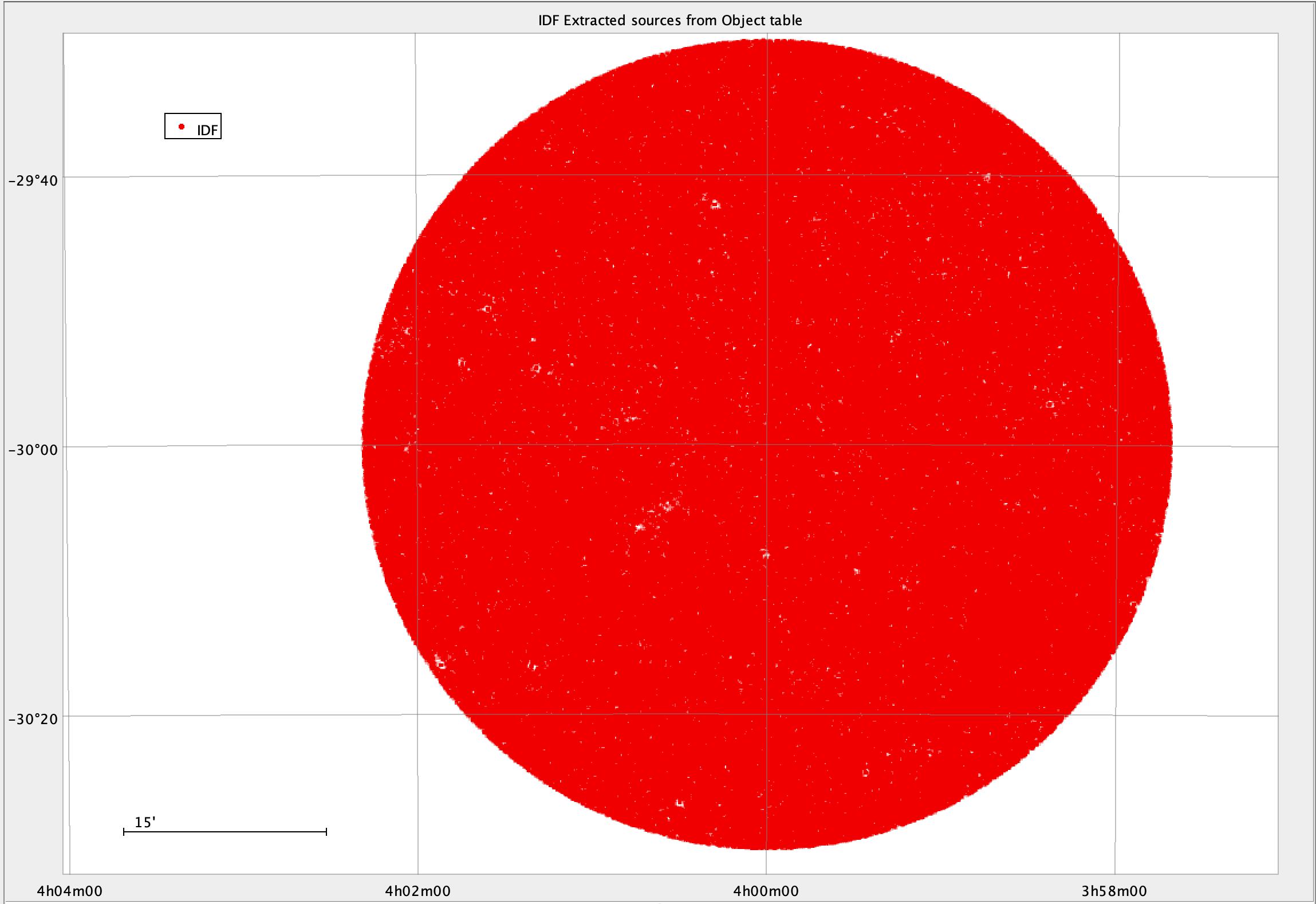
Fig. 9 Object’s sources from IDF DP0.2 catalog#
We note some large holes in the FrDF data, and if we look at the simulated images, we see extended and bright sources corresponding to the holes described above. See, for example, the following figures.
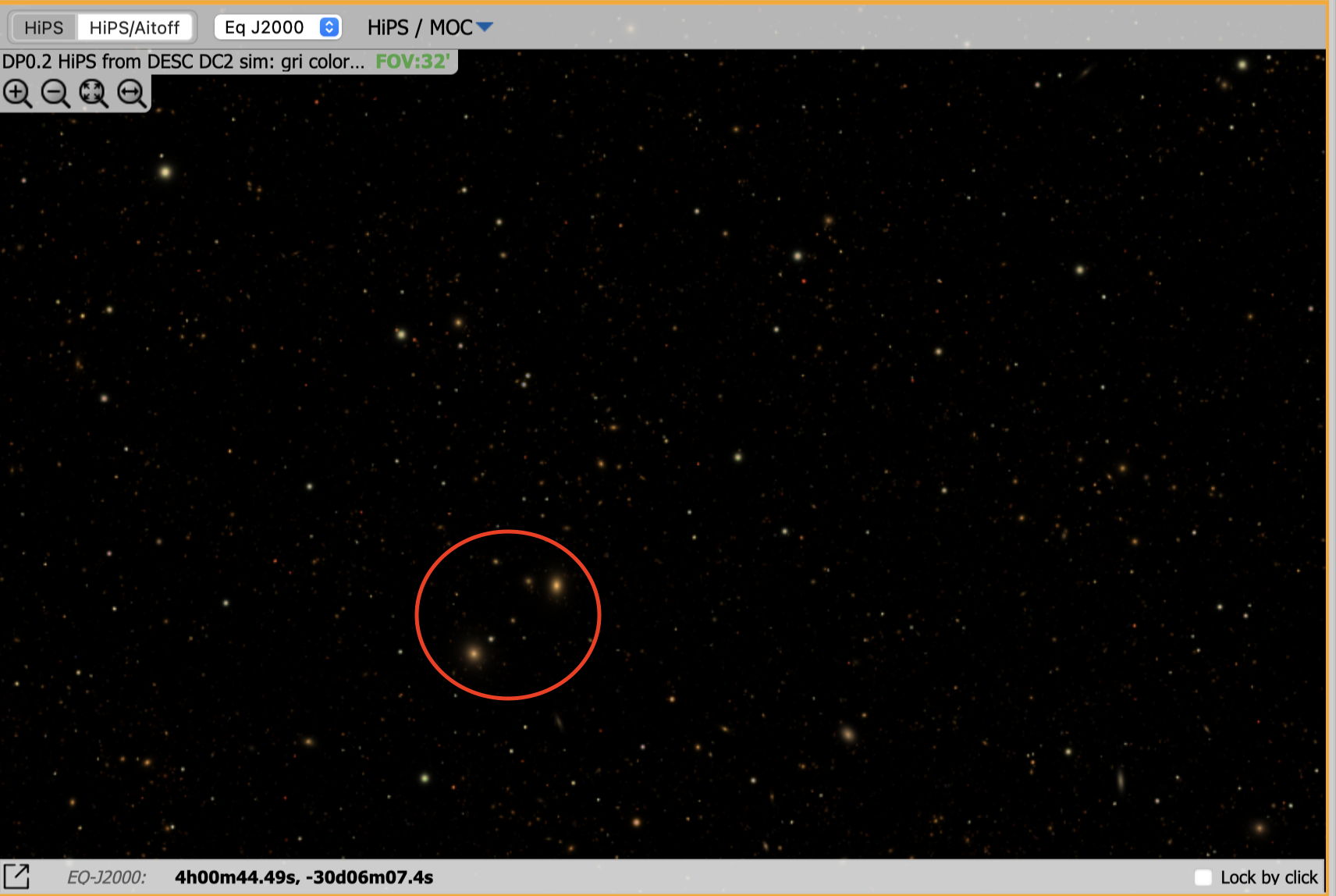
Fig. 10 In the presence of bright extended sources, the processing of DP0.2 produced different results in FrDF and IDF: IDF processing (represented by a dark magenta cross in the figure) detected more sources than FrDF processing (represented by a yellow circle in the figure).#
Is this due to the different version of the pipeline used? The analysis is available as notebook and as exported html.
Coordinates#
After the matching process, we obtained two catalogs with the same number of entries (395,865); we lost only a few FrDF sources and 508 IDF sources.
The results show a very good positional fit; almost all the sources are separated by less than 0.2 arcseconds (see next figure):
Fig. 11 Distribution of sky position differences for the Object table. The top figure shows a zoom on the positions of extracted sources.#
We can conclude, with respect to the coordinates, that the processing at FrDF and IDF is equivalent in this case, but we have to find the discrepancy in the number of sources generated.
Magnitude#
We analyzed the magnitudes in all six bands available in the table. The magnitudes were extracted from the flux called <band>cModelFlux, which is described as: “Flux from the final cmodel fit, forced on the <band>-band.”
For each magnitude, we plotted the distribution for each catalog and the differences between magnitudes for each corresponding source.
The distributions of magnitude in all the bands are almost the same, with only a few outliers, and this is confirmed by the difference distribution.
An example is shown in the following figure, illustrating the distribution of magnitude for the u band (note: both FrDF and IDF are plotted, but the distributions are almost the same. Please use the interactive notebook or interactive HTML to check it):
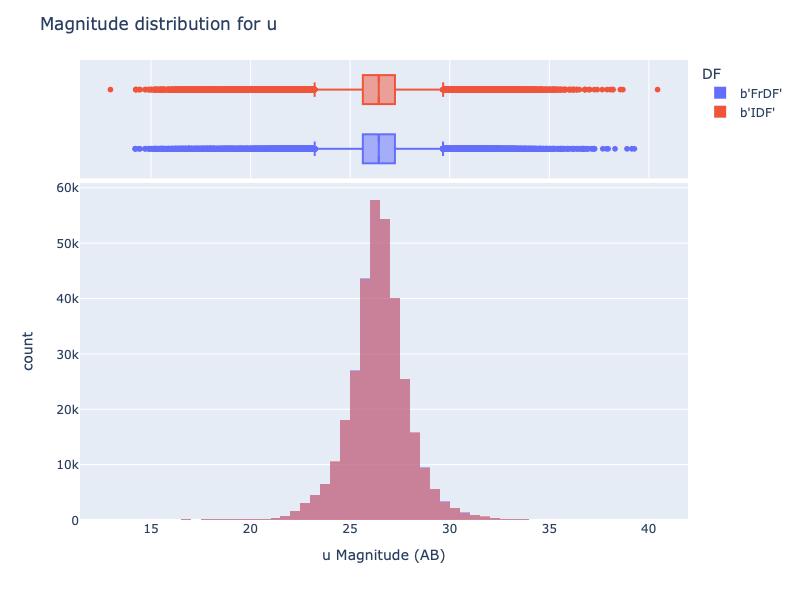
As mentioned, the distributions are almost indistinguishable, and this is also confirmed by the distribution of the magnitude difference, for example, for the u band, as shown in the next image:
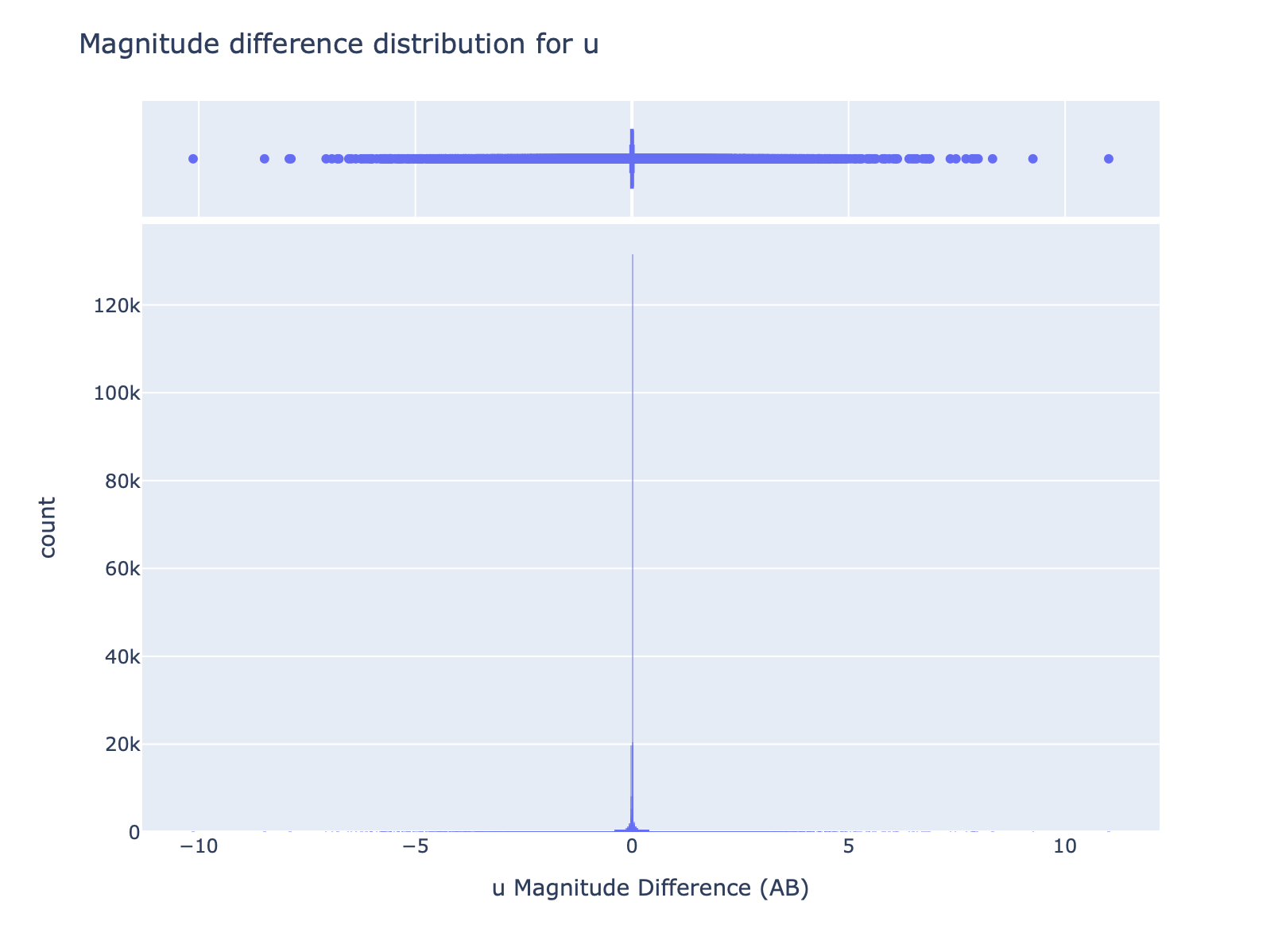
The charts above (and for all other photometric bands) could be generated via interactive notebook or explored via interactive HTML.
Also regarding magnitude, we can conclude that the object table produced at FrDF is equivalent to the one produced at IDF (with the caveat about the difference in the number of sources; see above).
Source Table#
The Source table contains astrometric and photometric measurements (143 columns) for sources detected in the individual PVIs.
For the source table we used a query with a small radius (0.01 deg) to avoid problem in catalogs matching. In this case the number of sources available in the two catalogs is the same (561,385).
Coordinates#
In this case, there are no evident holes or discrepancies in the plotted positions. See the figure below, where the source from IDF is shown in red, and the one from FrDF is shown in blue.
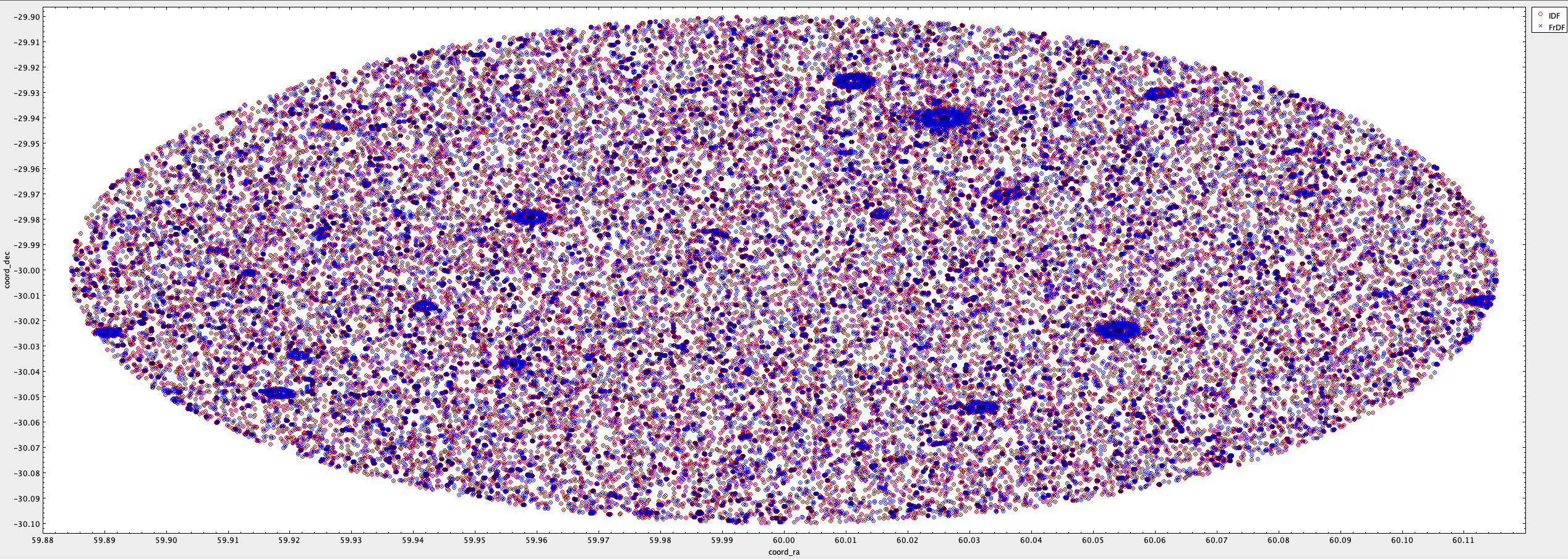
Fig. 12 Sources extracted from FrDF catalog (in blue) and from IDF catalog (in red).#
And also the further analysis show that there are no differences at all between Source’s position derived a FrDF and derived at IDF.
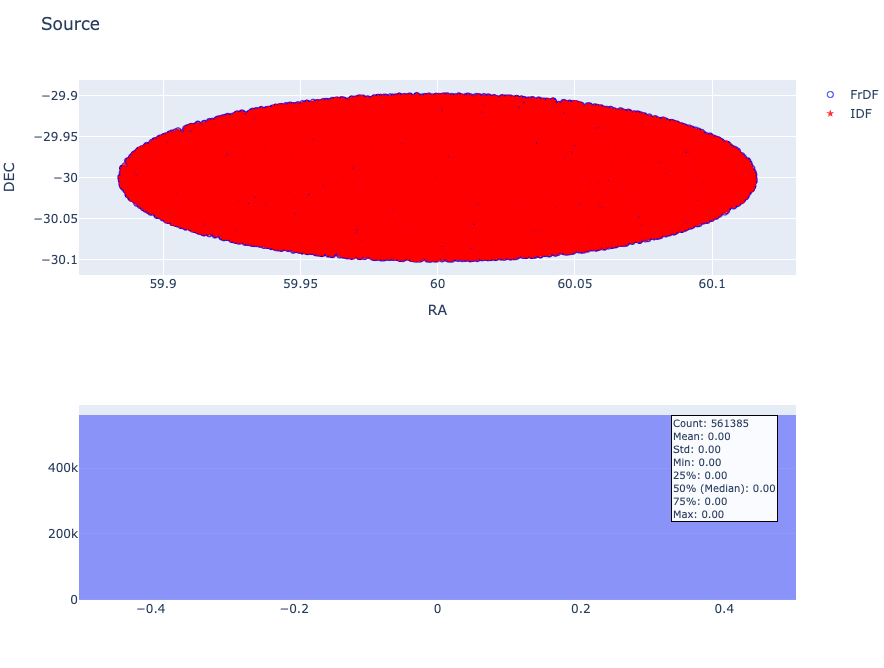
Fig. 13 Distribution of sky position differences for the Source table. The top figure shows a zoom on the positions of extracted sources, showing no differences.#
Magnitudes#
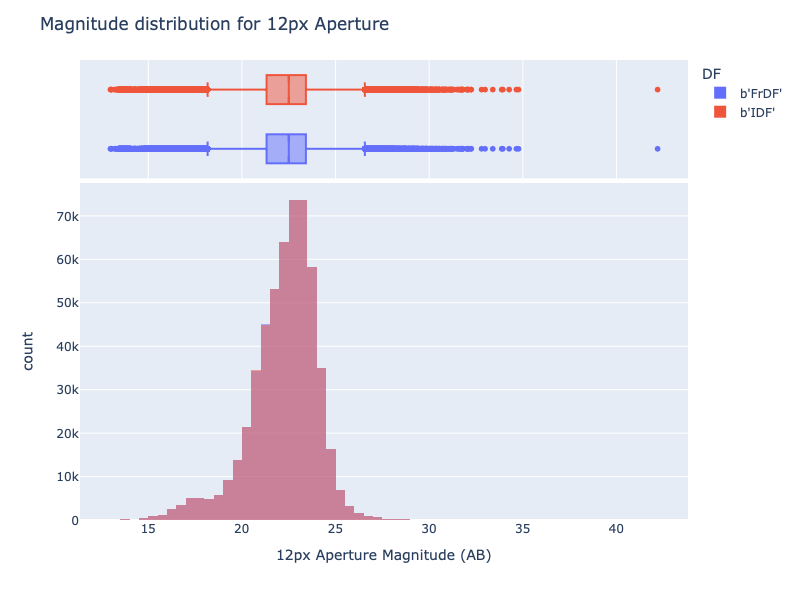
For the magnitudes, we analyzed data derived from 13 flux measurements: 9 magnitudes estimated at different apertures (converted from ap<aperture>Flux, which is the flux within a <aperture>-pixel aperture), and 4 other magnitudes:
skymag from skyFlux: background flux in annulus around the source
psfmag from psfFlux: flux derived from linear least-squares fit of PSF model forced on the calexp
gaussianmag from GaussianFlux: flux from Gaussian Flux algorithm
calibmag from calibFlux: flux within a 12.0-pixel aperture
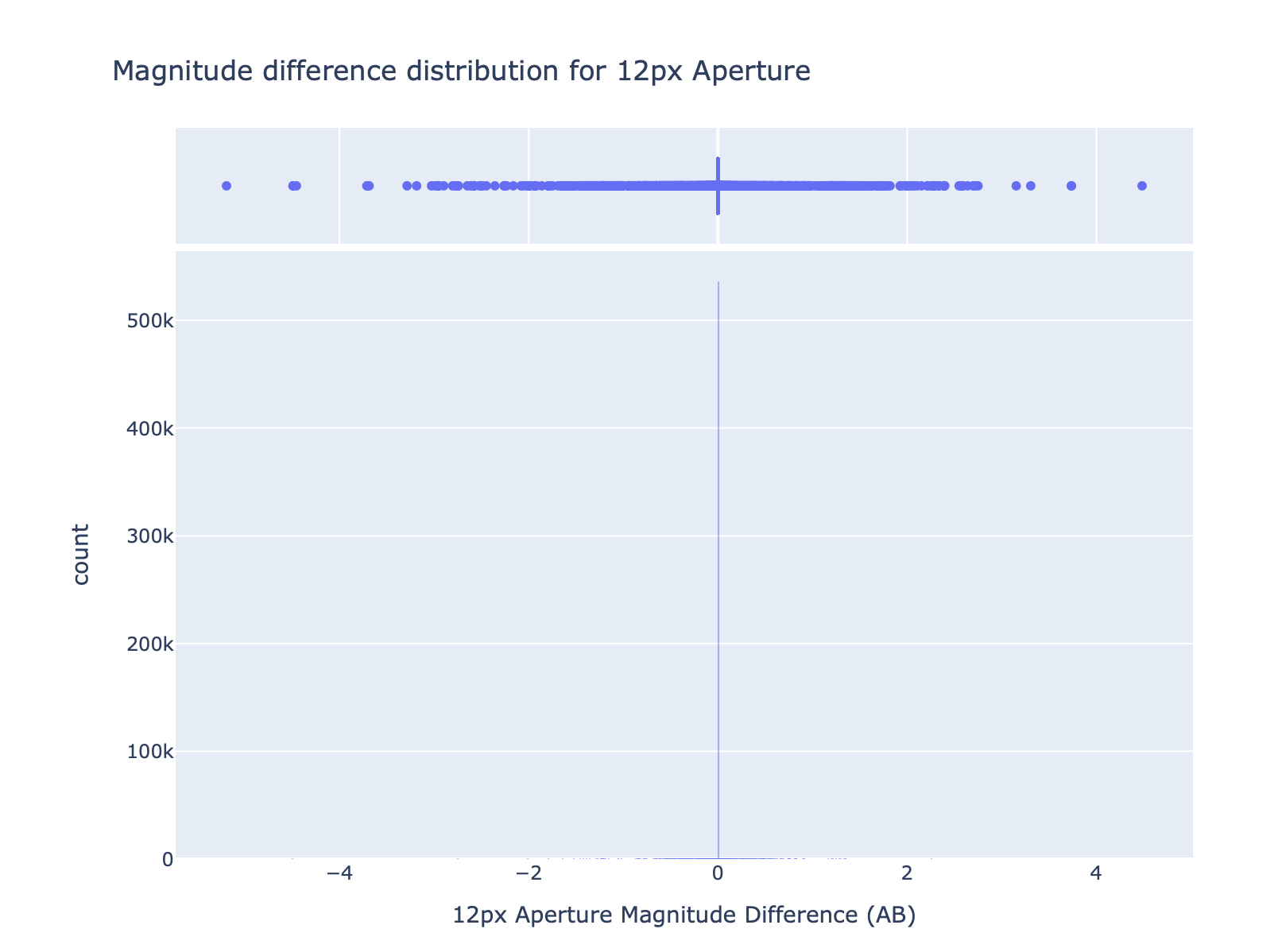
Also, for the magnitudes, the results are almost the same, confirming that FrDF processing is able to reproduce the data produced at IDF.
ForcedSource Table#
The ForcedSource table contains forced photometry on the individual PVIs at the locations of all detected objects (38 columns).
In this case, the number of lines in the catalogs is not the same: the FrDF ForcedSource table contains 1,643,290 lines, while the IDF ForcedSource table contains 1,642,866 lines.
Coordinates#
For this table there is no clear evidence of hole in the sky:
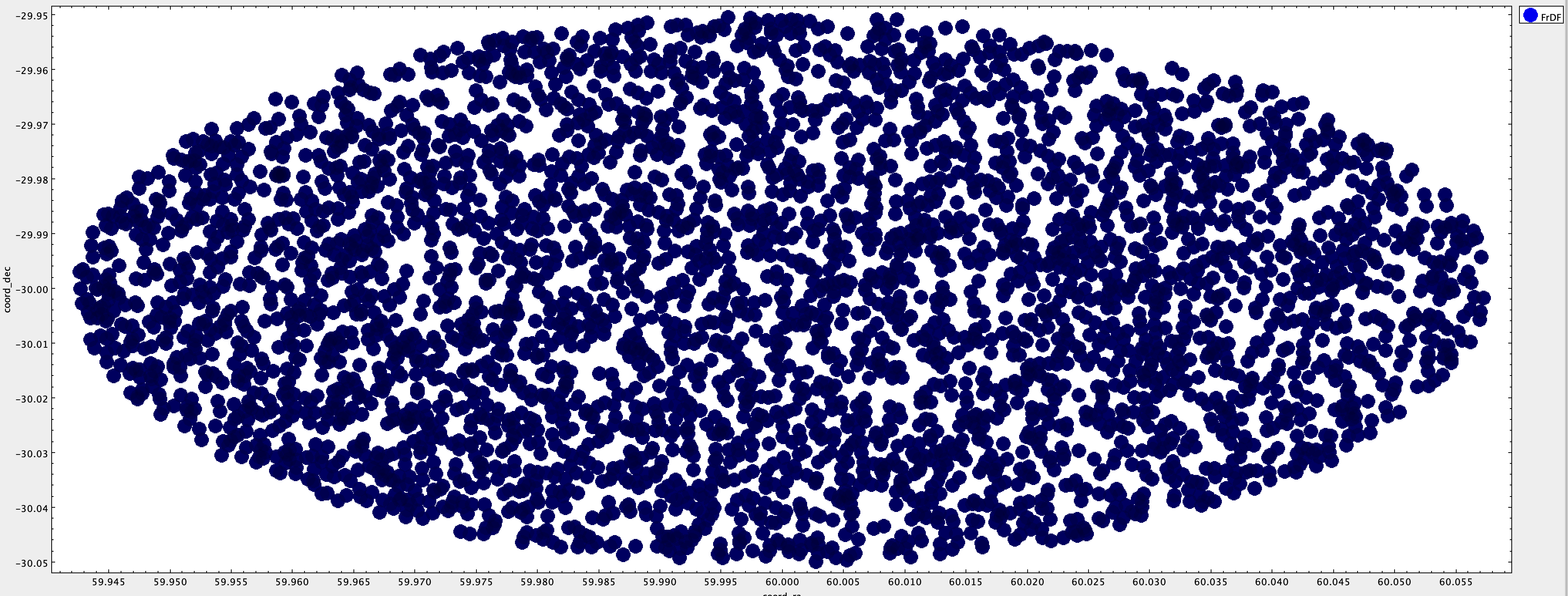

We proceeded to match the catalogs to obtain two identical catalogs in terms of the number of lines. All the IDF ForcedSource sources have been matched, and the distribution of the separations shows a really good match in this case as well.
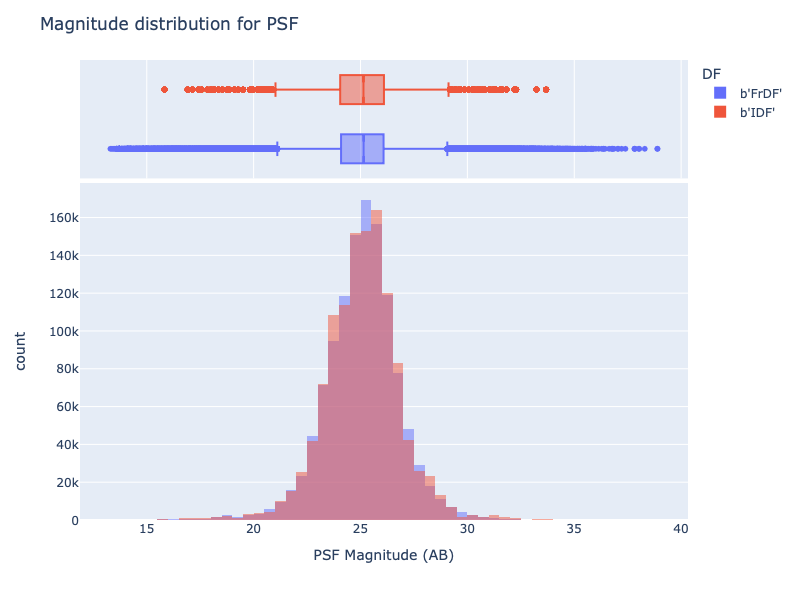
Magnitudes#
For the magnitudes, we analysed the two bands available in the table. The magnitudes have been extracted from the following columns:
psfFlux: Flux derived from linear least-squares fit of PSF model forced on the calexp
psfFluxDiff: Flux derived from linear least-squares fit of PSF model forced on the image difference
For each magnitude, we plotted the distribution for each catalogue and the differences between magnitudes for each corresponding source.
In this case, the distribution of magnitude shows small differences (also, it is statistically almost identical); the differences are mainly due to the outliers, as shown by the box plot.
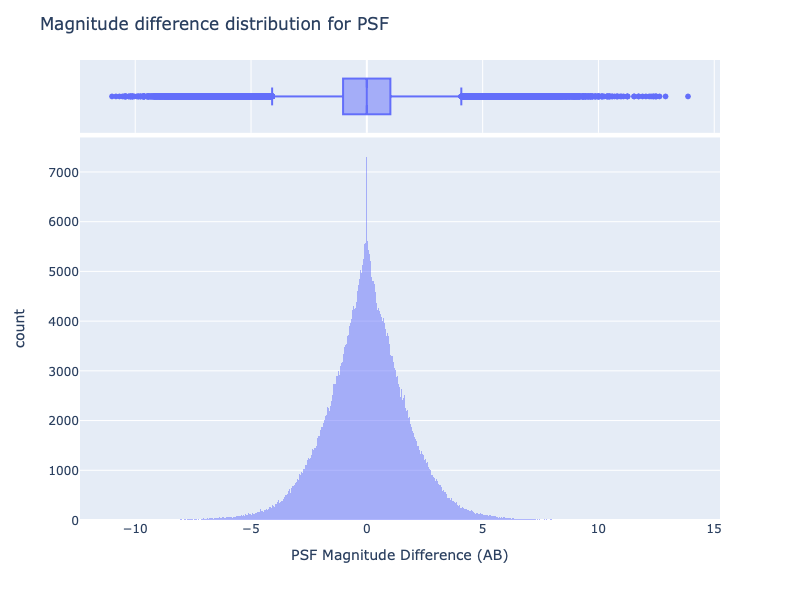
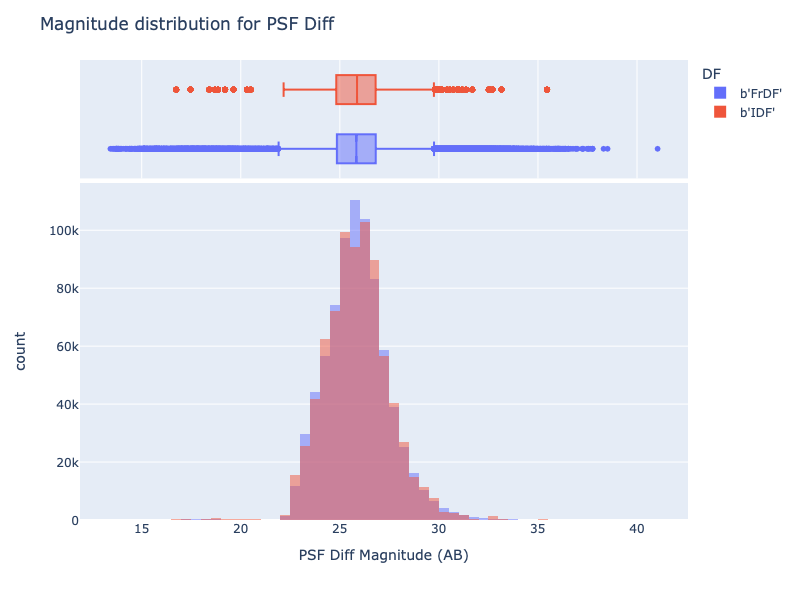
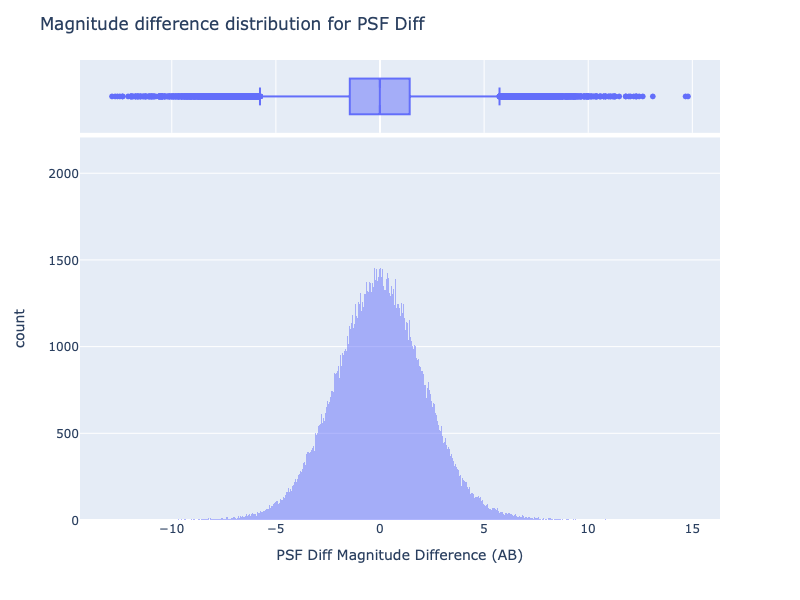
These differences must be analysed to understand the reason for such behaviour.
DiaObject Table#
DiaObject contains derived summary parameters for DiaSources that are associated by sky location, including lightcurve statistics. The table has 137 columns. The retrieved table contains the same number of lines (91,954).
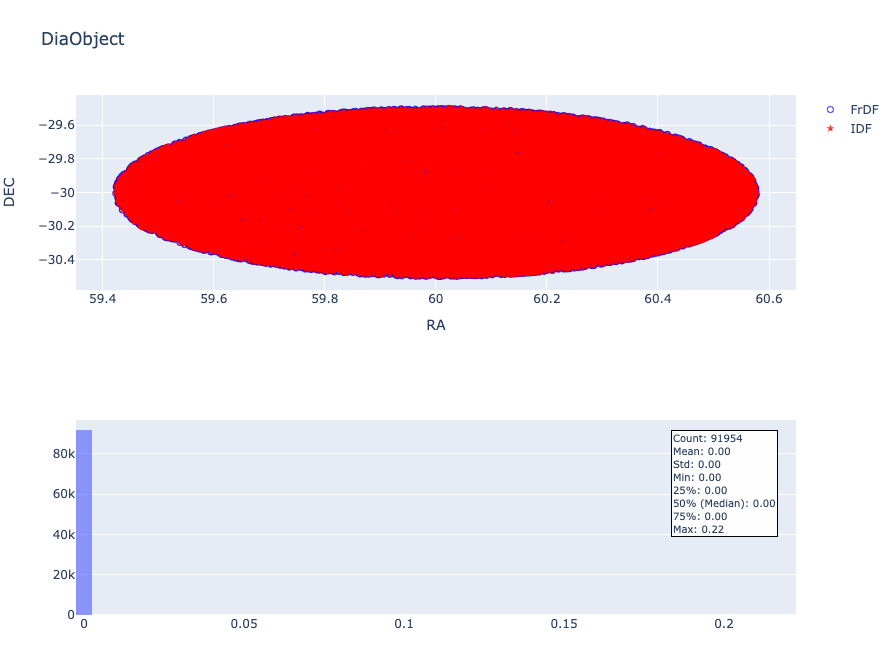
Coordinates#
For this table, the matching between FrDF and IDF is perfect, as shown in the next image (note: the top plot is a zoomed view of the entire region):
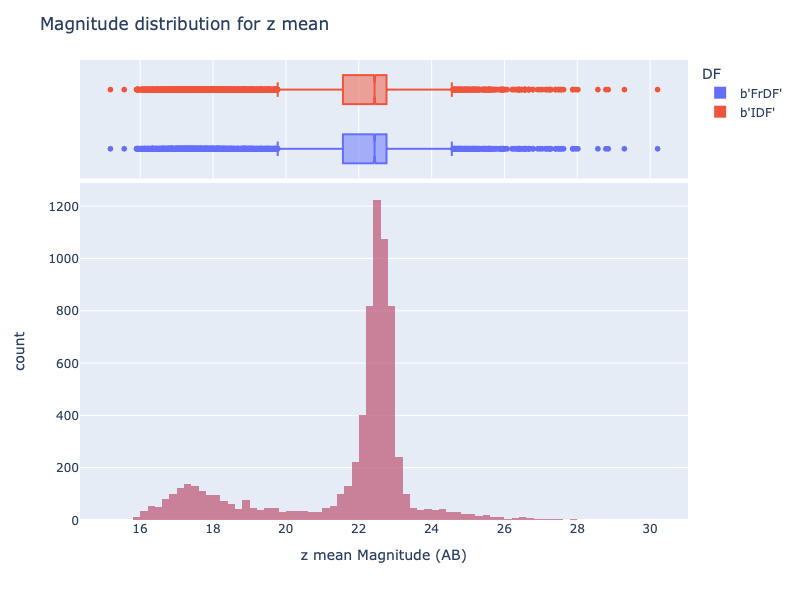
Magnitudes#
For the magnitudes, we analysed the flux for each band extracted from the columns <BAND>PsfFluxMean, defined as the weighted mean of diaSource PSF flux.
For magnitudes, as for coordinates, the results match perfectly.
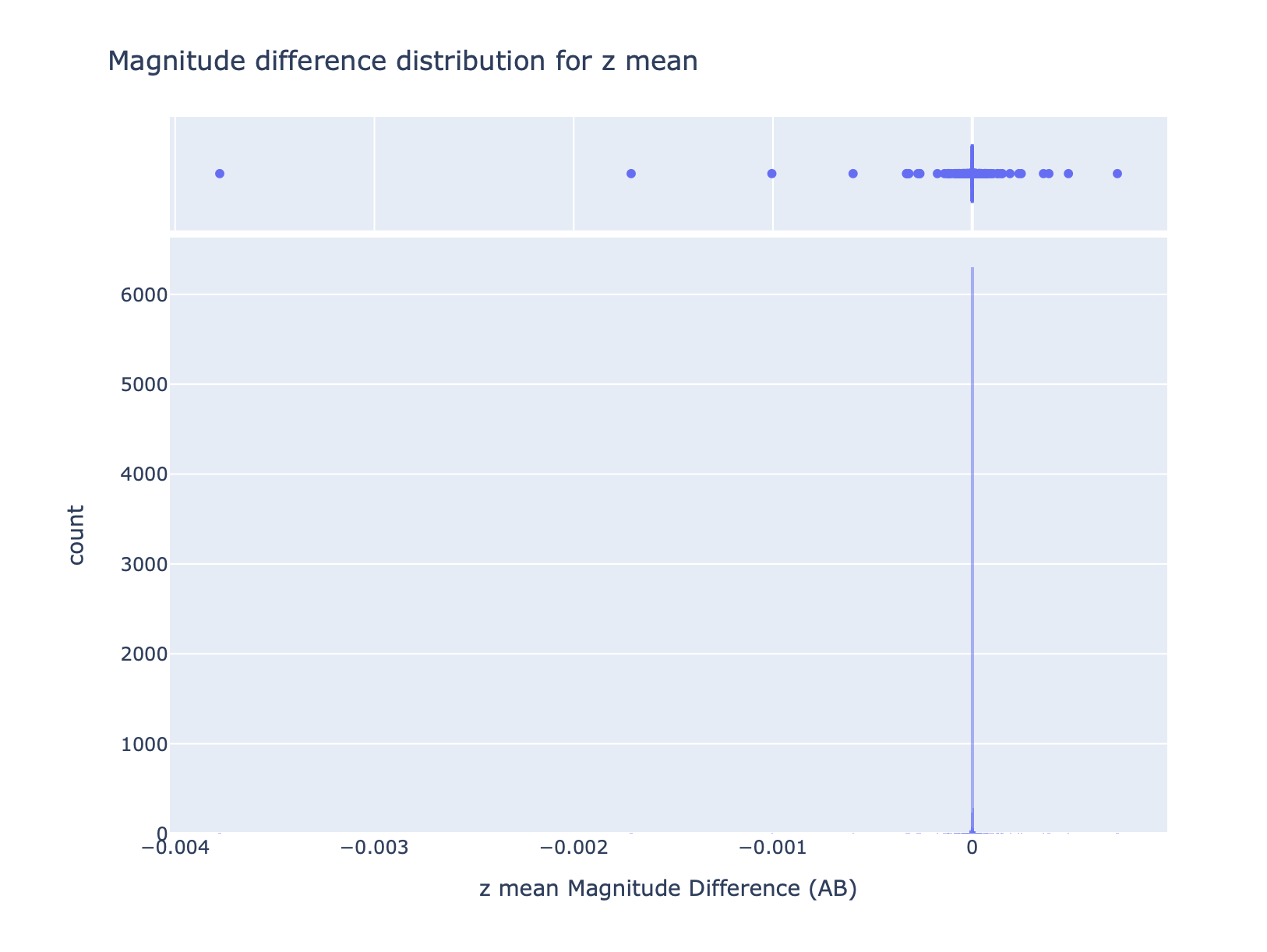
DiaSource Table#
The DiaSource table contains astrometric and photometric measurements for sources detected in the difference images (66 columns).
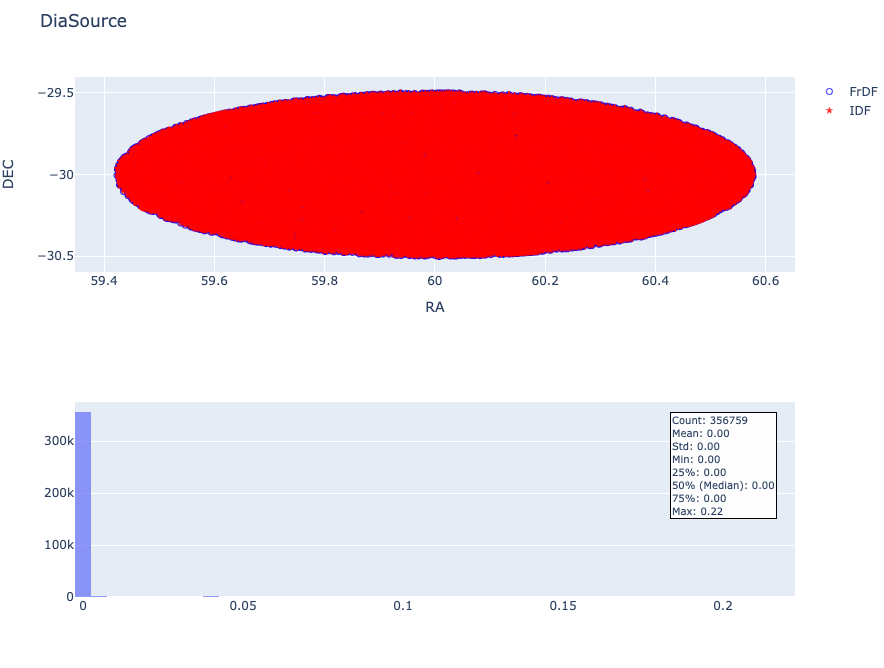
Both the IDF and FrDF retrieved tables contain the same number of sources: 356,759.
Coordinates#
Also, for the DiaSource table, there are no problems with the coordinates, as shown in the following image.
Magnitudes#
In our magnitude analysis, we examined three fluxes available in the table. The magnitudes were extracted from the following columns:
apFlux: Flux within a 12.0-pixel aperture
psFlux: Flux derived from a linear least-squares fit of the PSF model
totFlux: Forced PSF flux measured on the direct image
For each magnitude, we plotted the distribution for each catalog and the differences between magnitudes for each corresponding source.
As for the ForcedSource table, there are few differences in the distribution, as shown, for example, for the tot magnitude.
But overall, there is a good fit.
ForcedSourceOnDiaObject Table#
ForcedSourceOnDiaObject contains forced photometry on the individual PVIs at the locations of all DiaObjects.
With this specific table, we found a major problem: the FrDF table doesn’t contain fluxes at all (all the fluxes are set to NaN).
We checked, and the problem occurs during the pipeline processing because the fluxes are set to NaN also in the Parquet file.
We need to investigate it to find the reason for the problem.
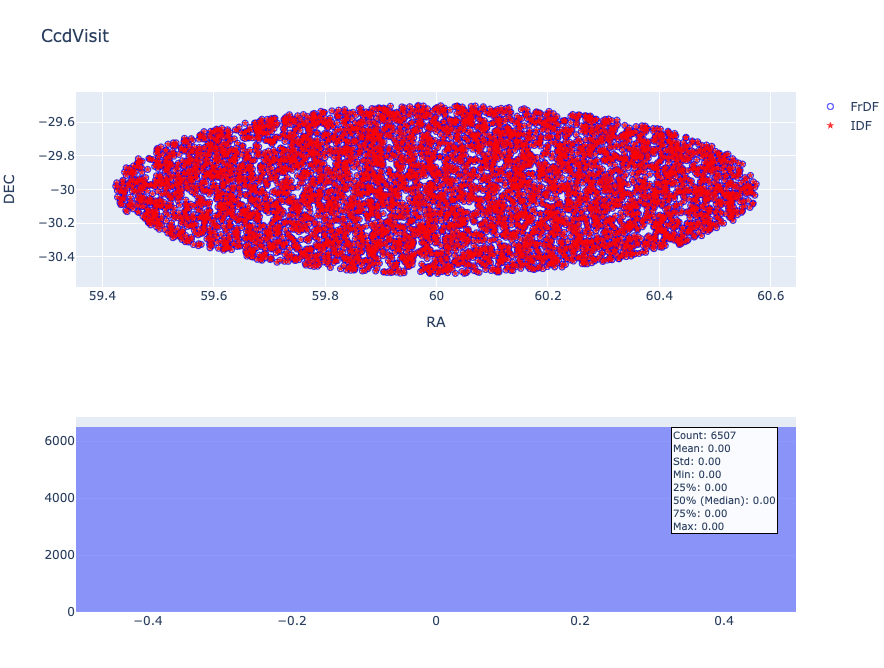
Visit and CcdVisit Tables#
The Visit table contains individual visit information, including band, airmass, exposure time, and so on (15 columns).
The CcdVisit table contains individual CCD (detector) information, including measured seeing, sky background, and zeropoint (30 columns).
For these tables, there are no fluxes to analyse and, as expected, there is a perfect coincidence between the positions.
References#
Quentin Le Boulc'h, Fabio Hernandez, and Gabriele Mainetti. The Rubin Observatory's Legacy Survey of Space and Time DP0.2 processing campaign at CC-IN2P3. EPJ Web Conf., 295:04049, 2024. doi:10.1051/epjconf/202429504049.
Daniel L. Wang, Serge M. Monkewitz, Kian-Tat Lim, and Jacek Becla. Qserv: a distributed shared-nothing database for the lsst catalog. In State of the Practice Reports, SC '11, 12:1–12:11. New York, NY, USA, 2011. ACM. doi:10.1145/2063348.2063364.
LSST Dark Energy Science Collaboration (LSST DESC), Bela Abolfathi, David Alonso, Robert Armstrong, Éric Aubourg, Humna Awan, Yadu N. Babuji, Franz Erik Bauer, Rachel Bean, George Beckett, Rahul Biswas, Joanne R. Bogart, Dominique Boutigny, Kyle Chard, James Chiang, Chuck F. Claver, Johann Cohen-Tanugi, Céline Combet, Andrew J. Connolly, Scott F. Daniel, Seth W. Digel, Alex Drlica-Wagner, Richard Dubois, Emmanuel Gangler, Eric Gawiser, Thomas Glanzman, Phillipe Gris, Salman Habib, Andrew P. Hearin, Katrin Heitmann, Fabio Hernandez, Renée Hložek, Joseph Hollowed, Mustapha Ishak, Željko Ivezić, Mike Jarvis, Saurabh W. Jha, Steven M. Kahn, J. Bryce Kalmbach, Heather M. Kelly, Eve Kovacs, Danila Korytov, K. Simon Krughoff, Craig S. Lage, François Lanusse, Patricia Larsen, Laurent Le Guillou, Nan Li, Emily Phillips Longley, Robert H. Lupton, Rachel Mandelbaum, Yao-Yuan Mao, Phil Marshall, Joshua E. Meyers, Marc Moniez, Christopher B. Morrison, Andrei Nomerotski, Paul O'Connor, HyeYun Park, Ji Won Park, Julien Peloton, Daniel Perrefort, James Perry, Stéphane Plaszczynski, Adrian Pope, Andrew Rasmussen, Kevin Reil, Aaron J. Roodman, Eli S. Rykoff, F. Javier Sánchez, Samuel J. Schmidt, Daniel Scolnic, Christopher W. Stubbs, J. Anthony Tyson, Thomas D. Uram, Antonia Sierra Villarreal, Christopher W. Walter, Matthew P. Wiesner, W. Michael Wood-Vasey, and Joe Zuntz. The LSST DESC DC2 Simulated Sky Survey. \apjs , 253(1):31, March 2021. arXiv:2010.05926, doi:10.3847/1538-4365/abd62c.